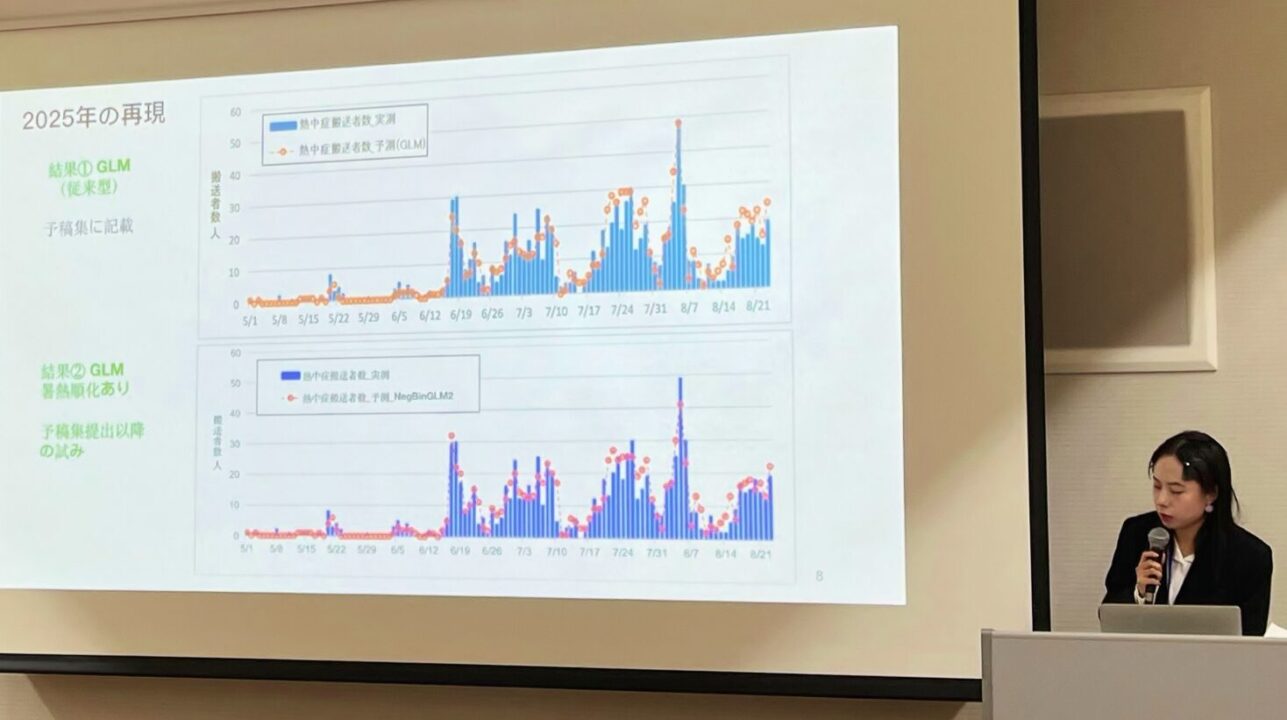
●さいたま市での熱中症救急搬送を分析(本紙学生記者) 2025 11/16 県民公論 2025年11月16日2025年12月6日 詳しくは上をクリックしてご覧ください 【編集局】気象が及ぼす人体の変調について調べる日本有数の組織である「日本生気象学会(所沢市)」による研究発表大会が、11月7日から9日にかけて公立鳥取環境大学で開催され、本紙の金雨薇(きんうび)留学生記者(埼玉大学大学院理工学研究科)が、さいたま市における熱中症患者の救急搬送数の分析結果を発表しました。 研究発表をする金雨薇学生記者 金雨薇留学生記者は「この研究によって、熱中症発症者の早期救急搬送や救急体制の確立、熱中症の予防対策に役立つことができれば、留学して生活しているさいたま市への恩返しとなります。特に、さいたま市が推進しているWHO(世界保健機関)が推奨する「セーフコミュニティ」の「子どもの安全対策」や「高齢者の安全対策」の参考にして頂ければうれしいです。」と語っています。以下、発表内容です。 GLM(一般線形モデル)とは、1つ以上の予測変数と1つの連続応答変数間の統計的関係を表すために、最小二乗回帰手法を使って計算を実行する分散分析(ANOVA)手順です。 発表が掲載された日本生気象学会雑誌 研究発表の内容(日本生気象学会雑誌Vol.62 №2より) 発表が終わって、ほっとひと息。「鳥取環境大学」についてはここをクリックしてご覧ください 詳しくは上をクリックしてご覧ください(さいたま市HPへ) 詳しくは上をクリックしてご覧ください(さいたま市HPへ) 詳しくは上をクリックしてご覧ください 県民公論 URLをコピーしました! ●日本ラオス民間外交レポート ●防衛大学校開校祭、ラオスを始めアジア友好各国軍の展示を視察 この記事を書いた人 水野 臣次 編集局長 趣味はさいたま市、ペットはヌゥ。 明るく楽しいオモシロさいたま市を、みんなで作りたいヌゥ! 関連記事 ●6月さいたま市議会 全質問者登場 2026年6月27日 🔷市役所移転を現職市長として迎える意欲 2026年6月4日 ●童謡「あめふり」から学ぶ「人の道」 2026年6月4日 ●本紙留学生記者に「優秀選挙報道賞」 2026年5月28日 ●宮澤賢治 埼玉来県110周年 2026年5月9日 ●さいたま市民のラオスでの活躍 2026年4月2日 ●県民公論2月市議会&新年度特集です 2026年3月31日 ●新年度の市政の考え方と進め方(施政方針) 2026年3月28日